
Creating a Data Science Culture
Virtually all organizations today are searching for new methods to extract more usable information from the vast amounts of data being amassed from an ever-growing number of enterprise systems, applications, and tools. In this quest to drive analytics maturity and modern data-driven decision-making, businesses must evolve from their traditional descriptive analytics focus to one that includes advanced, predictive and prescriptive analytics. Due to the wide availability and acceptance of AI and Machine Learning models, organizations can now more readily advance their analytics with unprecedented opportunities to analyze larger and more complex data, discover data patterns, predict outcomes, and improve decision-making.
As advanced analysis methods become a critical differentiator, companies need to invest in creating a data science culture that spans a broad spectrum of roles and use cases. But organizations choosing to implement data science strategies to gain competitive advantage should know this comes at a cost and is easier said than done due to the demand for qualified data science skills. In addition, successful analytics and data science teams need more than the technical expertise provided by data scientists — they need to team with subject matter experts who understand the business, data, and performance drivers.
It’s going to take time for organizations to add data scientists to their teams, and some will never do so. For many companies, a practical way to satisfy this requirement is to leverage existing talent, such as business analysts or power users who may not have formal computer science, statistics, or data modeling education, but can perform more advanced analysis to improve decision-making. These people, often referred to as citizen data scientists, cannot replace per se the professional data scientist, but can be utilized across the organization in various roles and capacities based on their level of competency and understanding of the business. With the proper tools and on-the-job training, more and more data and analytics professionals can improve their data science literacy and over time establish themselves as citizen data scientists.
For those companies that have accredited data scientists on their teams, there is another aspect that is sometimes overlooked — data scientists often need to prepare unique datasets from live production data sources to fully develop, train, and ultimately operationalize their AI and Machine Learning models and algorithms within the business. This can now be accomplished through modern data and analytics platforms that simplify the task of blending and preparing real live production data tailored for specific use cases and models.
Creating a Data Science Culture
Virtually all organizations today are searching for new methods to extract more usable information from the vast amounts of data being amassed from an ever-growing number of enterprise systems, applications, and tools. In this quest to drive analytics maturity and modern data-driven decision-making, businesses must evolve from their traditional descriptive analytics focus to one that includes advanced, predictive and prescriptive analytics. Due to the wide availability and acceptance of AI and Machine Learning models, organizations can now more readily advance their analytics with unprecedented opportunities to analyze larger and more complex data, discover data patterns, predict outcomes, and improve decision-making.
As advanced analysis methods become a critical differentiator, companies need to invest in creating a data science culture that spans a broad spectrum of roles and use cases. But organizations choosing to implement data science strategies to gain competitive advantage should know this comes at a cost and is easier said than done due to the demand for qualified data science skills. In addition, successful analytics and data science teams need more than the technical expertise provided by data scientists — they need to team with subject matter experts who understand the business, data, and performance drivers.
It’s going to take time for organizations to add data scientists to their teams, and some will never do so. For many companies, a practical way to satisfy this requirement is to leverage existing talent, such as business analysts or power users who may not have formal computer science, statistics, or data modeling education, but can perform more advanced analysis to improve decision-making. These people, often referred to as citizen data scientists, cannot replace per se the professional data scientist, but can be utilized across the organization in various roles and capacities based on their level of competency and understanding of the business. With the proper tools and on-the-job training, more and more data and analytics professionals can improve their data science literacy and over time establish themselves as citizen data scientists.
For those companies that have accredited data scientists on their teams, there is another aspect that is sometimes overlooked — data scientists often need to prepare unique datasets from live production data sources to fully develop, train, and ultimately operationalize their AI and Machine Learning models and algorithms within the business. This can now be accomplished through modern data and analytics platforms that simplify the task of blending and preparing real live production data tailored for specific use cases and models.
Empowering Citizen Data Scientists
Equipping citizen data scientists with access to data through the right analytics tools and technologies will encourage the innovative and experimental approaches to explore and uncover hidden insights from their data. In the past, machine learning (ML) and artificial intelligence (AI) required extensive programming skills and a deep math knowledge. Nowadays, new technologies make the AI and ML models available to a wider audience.
One example of a new technology is DataClarity’s Analytics and Data Science platform, an easy-to-use tool that allows a citizen data scientist to quickly leverage sophisticated data science capabilities. With no programming or data science experience, business users can perform advanced analysis. Built-in data science models are applied through the formulas where users can readily input data and variables in an intuitive way. The underlying algorithms are executed using DataClarity Python (a Python installation included in DataClarity Platform), MLlib (Apache Spark’s machine learning library), and Smile (a machine learning engine).
Built-in models in DataClarity offer a unique opportunity to use complex algorithms and at the same time provide flexibility by specifying parameters that work for your data, specific use case, and the story behind it. Let’s look at the most popular examples how citizen data scientists can use built-in models to perform the following data manipulation techniques: forecasting, clustering (segmentation), and outliers detection.
Time Series Forecasting
Time series forecasting can help companies better understand future demand for products sold, expected website traffic during a busy season, predicting maintenance costs, and so on. These questions could be answered with the use of data science considering a sequence of previous observations stored in time order.
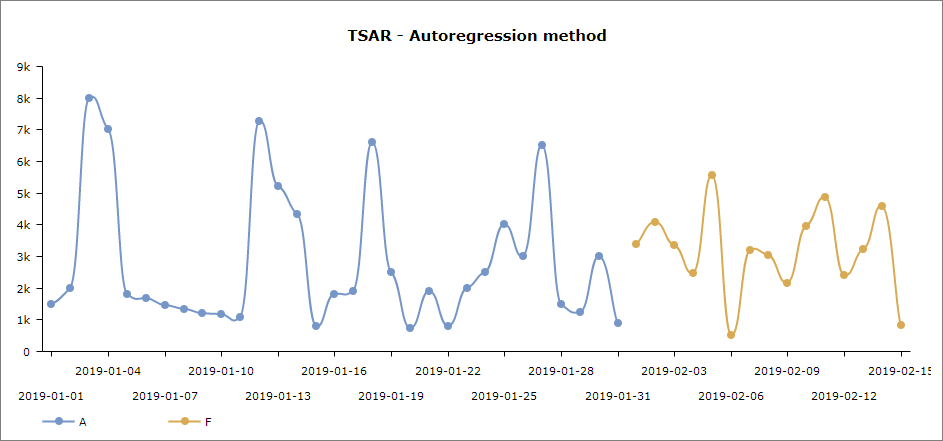
To make the predictions, models use actual values and apply various methods to display the forecasted results. DataClarity’s built-in models use various methods like Moving Average, Autoregression, Seasonal Autoregressive Integrated Moving Average, Holt-Winters Exponential Smoothing, and various combinations of these methods. You may choose one or another method that works best with your data. For example, if you know the data is seasonal, the respective method with a seasonality component would do a better job in predictions.
The steps are simple, explore the list of built-in functions that can perform time series forecast using various algorithms, drag a model, modify the parameters, and apply to the visualization.

The following examples show a sales forecast based on the Autoregression method and Holt-Winters Exponential Smoothing method. The chart shows actual values (A) based on which the prediction is built, and forecasted values (F), also marked by a different color.

Outlier Detection
Understanding your outliers and their origin is important as it might change your analysis and overall data patterns. They can just be anomalies or errors in the input data or novelties in data. Excluding outliers can help business to see the real picture for the rest of the data without skewing it.
Outliers are the data points that deviate from the overall pattern of your data points. DataClarity’s built-in models are using various methods like Local Outlier Factor, the Mahalanobis distance, Isolation Forest, Elliptic Envelope, and others. Each model has its own recommendations when it works best.
The following are examples of outliers detected based on built-in models that are using LOF (Local Outlier Factor) and Isolation Forest methods, and then visualized in the scatterplot chart. After applying the model, data points are divided in the outlier and the inlier data points. In the example below, ‘1’ is assigned to inliers (falling in the overall pattern) and ‘-1’ is assigned to outliers.


This is how the calculation with Isolation Forest method is defined in DataClarity.

Clustering and Segmentation
Another example of complex statistical and analytical calculations in data preparation and visualization is segmentation. For example, your analysis may require grouping product types based on sales, segmenting customers based on their purchase behavior, etc.
To perform such analysis tasks, clustering models and algorithms come into play. Clustering is an unsupervised data science technique where the data is organized into different groups where data points inside the same group are more similar than the ones outside the group. It can be helpful in identifying a business problem area to be further explored.
When creating a calculation, business users explore the list of built-in functions that can create clusters using various algorithms. Some algorithms require specifying the number of clusters to be found as a parameter whereas other algorithms detect the number of clusters themselves. Again, depending on the data and knowledge of possible clusters, users may choose one or another model that is suitable.

The following are the examples of various clustering algorithms applied to the same data. Comparison of the clusters may help decide which clusters might be worth investigating more deeply. As clustering is the process of finding possible natural groupings in the data, you may also choose to experiment with other variables to see if there are any clusters of interest taking into consideration the data background.

Data Scientists can optimize and operationalize pre-curated models
If an organization has the advantage of an in-house data scientist developing complex models for various use cases, the challenge quickly becomes how to feed the models with live production data to train and optimize their performance. This can be especially challenging when the dataset does not exist and must be derived from multiple disparate data sources and types without the assistance of IT.
With DataClarity, you can connect to more than 100 data source types including popular databases, NoSQL sources, big data sources, modeled BI data, cloud apps, social media data, and many more. Using Data Preparation, you can combine multiple sources for a unified view of your data and prep it for analysis.
Having established access to production data, data scientists can start using script capabilities for running their R and Python models. The code is integrated into the platform as a simple calculation, and executed on the server based on the available connection, such as RServe or TabPy. The connection to the server can be created once and shared among the users who will be running the scripts in DataClarity.
Let’s look at an example with a model developed in R that detects outliers. To create a calculation in DataClarity, users insert lines of code, select the variables, and apply aggregation if needed. The calculation is ready to be applied to visualizations or datasets.

The following is the example of outliers detected based on the Python script and visualized in the scatterplot chart.

Continue your data science journey
Enabling your organization with the proper tools and training is just the first step in what can be a tremendously valuable journey for your business. For data science to pay major dividends, it need not be complex or the most sophisticated, but simply correct and accurate methods for analyzing data to improve decisions to take advantage of opportunities or solve challenges when they arise. Irrespective of the role and skill level, every person on the team can be successful employing data science methods, whether they be the citizen or formally trained data scientist.
To learn more about how DataClarity can advance your data science culture throughout your organization, please visit DataClarityAnalytics.com.